О илузији разума у машини


Седиш пред екраном. Куцаш питање. Притискаш тастер, и тај чин, толико обичан да га готово и не примећујеш, представља тренутак предаје: предајеш свој матерњи језик нечему што не поседује језик, него га врло успешно симулира.
У том тренутку, док чекаш одговор, верујеш да се с друге стране одвија процес размишљања. И то веровање није нужно наивно; оно је дубоко укорењено у начину на који људски ум функционише, у твојој еволуцијски условљеној потреби да у покрету препознаш вољу, да у обрасцу наслутиш намеру, да у одговору чујеш глас свести, да у сложености препознаш смисао. Оно те наводи да свему што личи на понашање припишеш унутрашњи живот.
Зато верујеш да машина „размишља”, да тражи информације, да слаже концепте, можда чак и да разуме шта си је питао. И ово последње, ово „разуме”, јесте управо она тачка на којој целокупна конструкција почива, а уједно и тачка на којој се она руши. Јер разумевање, у оном смислу у којем га ти доживљаваш, подразумева контекст, подразумева искуство, подразумева памћење које није само складиште података већ лични доживљај, подразумева унутрашњу тишину у којој се значење не израчунава већ сазрева, и подразумева тело које је осетило хладноћу да би знало шта значи реч „зима”.
Машина не зна шта је зима. Она зна да после речи „хладна” статистички често долази реч „зима”, и то јој је довољно да произведе реченицу коју ћеш ти доживети као смислену. То је природна људска пројекција, јер ми видимо лица у облацима, ми чујемо гласове у вихору ветра, и сада, када смо прочитали одговор, видимо разум у тексту који генерише алгоритам.
Међутим, то је илузија.
Овде би требало да будемо врло прецизни када користимо реч илузија. Јер оно што називамо илузијом није исто што и лаж, нити је исто што и грешка, већ је то процес опажања у којем наш ум конструише значење тамо где значење, у изворном смислу, не постоји.
Не постоји разум.
Не постоји мисао.
Не постоји чак ни разумевање речи онако како их ти разумеш, а ова последња тврдња захтева посебну пажњу, зато што имплицира нешто радикално: да је могуће произвести савршено граматички исправан, семантички кохерентан и убедљив текст без иједног тренутка свесности о томе шта тај текст значи.
У одговору алгоритма постоји само статистика, хладна и вишедимензионална математика чији је једини задатак да погоди шта долази следеће.
Ова хладноћа коју овде приписујемо статистици није метафора; она је буквални опис стања у којем не постоји субјект који осећа и не постоји ентитет којем је стало до исхода. Постоји само калкулација вероватноћа распоређених кроз простор ЛЛМ-а од неколико билиона параметара.
Сваки одговор који добијеш од језичког модела, свака песма, сваки програмски код, сваки есеј који те је одушевио својом „креативношћу”, заправо је само низ предвиђања следећег токена. Ови системи не баратају језиком; они баратају статистичким репрезентацијама језика, што је фундаментално другачија ствар.
Ово је почетна претпоставка од које полазимо и коју, чини се, морамо озбиљно да схватимо ако желимо да водимо искрен разговор о томе шта генеративна вештачка интелигенција јесте, а шта само изгледа да јесте.
Бројеви уместо речи: Архитектура пажње
Када унесеш реченицу у модел, ти му не дајеш речи, већ низ бројева. И ова наизглед тривијална чињеница заслужује далеко више пажње него што јој се обично придаје. Свака реч, или прецизније, сваки сегмент речи који модел препознаје као засебну јединицу, пролази кроз процес токенизације, то јест претварања у нумеричку репрезентацију коју статистички систем може да обрађује.
Оно што се при том губи јесте, разуме се, језик, у оном смислу у којем га ми доживљавамо: као живо ткиво значења, као нешто што носи тежину искуства и намере. То је први корак трансформације значења. Мада би се могло рећи да то и није толико трансформација колико превођење у други модалитет, у језик који машина разуме, а човек никада не би могао да прочита.
Оно што даље следи је механизам пажње (Attention Mechanism). Овај механизам није само техничко достигнуће; он представља фундаменталну промену у начину на који рачунарски системи процесирају секвенцијалне информације.
Старији системи за обраду природног језика, рекурентне неуронске мреже пре свега, читали су текст онако како и ми читамо књигу: секвенцијално, реч по реч, носећи са собом нешто налик краткорочном памћењу које је неизбежно бледело што је реченица бивала дужа. Ако се кључна информација налазила на почетку дугачког пасуса, а референца на њу тек на крају, систем је, метафорички речено, заборављао зашто је уопште почео да чита.
Трансформер, архитектура коју су Васвани и сарадници представили 2017. године у сада чувеном раду Attention Is All You Need, решава овај проблем на начин који је концептуално елегантан а рачунарски интензиван.
Трансформер не чита линеарно.
Он „гледа“ све одједном.
Ова констатација, носи огромну тежину, јер описује нешто што је заиста контраинтуитивно за људски ум навикнут на линеарни ток. Трансформер у истом тренутку обрађује све елементе улазне секвенце, израчунавајући за сваки пар токена меру њихове међусобне релевантности - такозвану тежину пажње. Суштина self-attention механизма јесте да сваки елемент улаза постаје и питање и одговор и вредност, а модел мери у којој мери информација коју носи један токен помаже да се разуме улога другог токена.
Ако имамо реченицу: „Мачка која је јурила пса била је брза“. Реч „била“ треба да зна на шта се односи. Модел зато „обраћа више пажње“ на реч „мачка“ него на „пас“, јер из структуре реченице учи да се „брза“ односи на мачку. Self-attention механизам ради управо то: свака реч процењује колико јој друге речи помажу да се правилно протумачи значење реченице.
Геометрија језика и векторско позиционирање
Вишезначност речи представља један од најстаријих проблема у рачунарској лингвистици. Чињеница да механизам пажње ово решава прилично елегантно, додељујући високу тежину вези између речи „мрежа” и „рибар” а ниску вези између „мрежа” и, рецимо, „односа”, открива нешто важно о природи овог система: он не разуме значење речи, али разуме структуру контекста у којем се речи појављују. То, дакле, није истинско разумевање контекста.
То је позиционирање вектора у вишедимензионалном простору.
Свака реч, односно сваки токен, представљена је као тачка у простору са хиљадама димензија, као вектор чија позиција не кодира значење у људском смислу, већ статистичке односе са свим другим токенима на којима је модел трениран. Механизам пажње мери углове и раздаљине између тих тачака користећи математичку операцију познату као скаларни производ (dot product), и управо ти углови и раздаљине одређују колико је један токен „важан” за други у контексту предвиђања следећег токена у низу. То је масивна матрица множења, softmax нормализација и пројекције кроз научене тежинске матрице, а све се то дешава у делићу милисекунде, паралелно, на хиљадама графичких процесорских јединица истовремено.
Узмимо реч „дуња” као пример. ЛЛМ не „зна” шта је дуња, али зна да се токен „дуња” статистички налази у близини токена „жута”, „ораси”, „слатко”, „Индекси”. Ово запажање, иако наизглед једноставно, указује на нешто што може бити врло узнемирујуће. Ако у свету језика, ЛЛМ може да управља речима са довољном прецизношћу да генерише кохерентне и информативне одговоре, а да притом нема никакву унутрашњу представу о стварности која стоји иза тих речи, шта то говори о природи самог језика?
И шта то говори о нама и о домету нашег сопственог разумевања света, које је, можда, такође „само” статистичко позиционирање, али реализовано на биолошкој и искуственој основи?
Модел не види свет.
Он види геометрију језика.
Али геометрија језика, како се испоставља, носи у себи запањујуће много информација о свету који смо описали речима.
Контролисана насумичност
Када ЛЛМ заврши са прорачуном, када измери све тежине и односе између свих токена у улазној секвенци, он долази до краја упита и стоји пред задатком који представља његову једину и искључиву функцију: да генерише следећи токен. Он попуњава празнину. Али начин на који то ради није строго предодређен.
Модел не бира једну исправну реч.
Он генерише расподелу вероватноћа преко свог целокупног речника, и из те расподеле, којом можемо да управљамо параметром који се зове температура, бира се један токен. Виша температура значи већу случајност, већи ризик, креативнији али и непредвидљивији излаз. Нижа температура значи конзервативнији и очекиванији одговор.
Ту престаје детерминизам и почиње игра на срећу, јер модерна генеративна вештачка интелигенција, у својој суштини, јесте управо то: софистицирана лутрија заснована на геометрији језика, спроведена у простору који ниједан човек не може да визуализује и брзином коју ниједан човек не може да испрати. И управо та комбинација математичке прецизности и фундаменталне случајности чини ове системе истовремено тако моћним и тако необјашњивим.
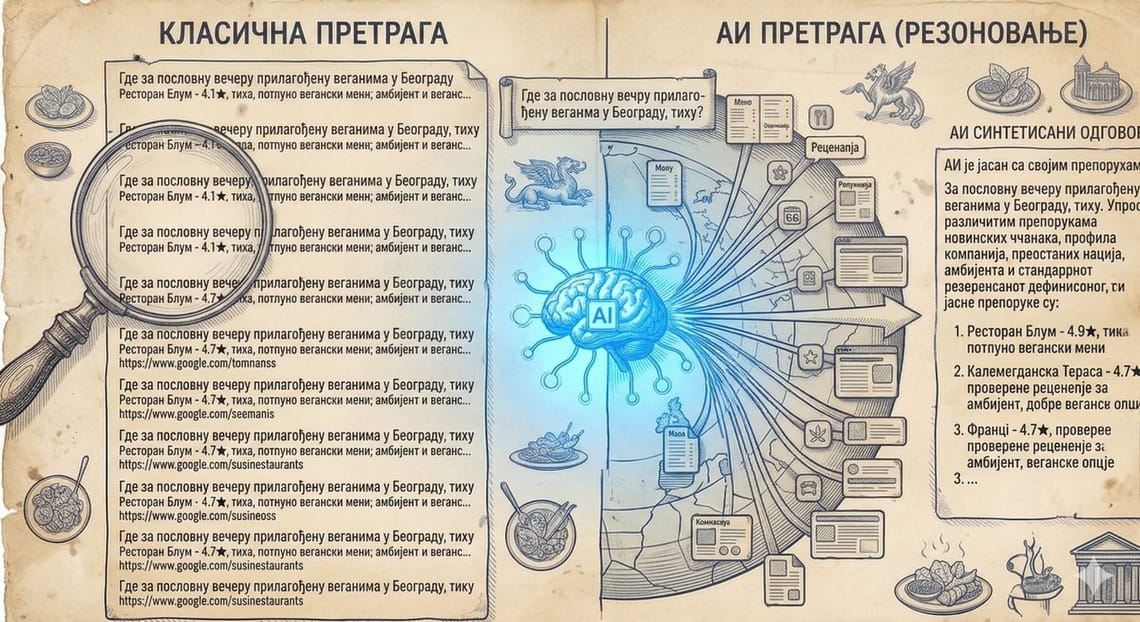
Већина људи полази од погрешне претпоставке када размишља о томе шта језички модел заправо ради. Замишљамо некакав механизам претраге који тражи одговарајућу „страницу“ да би прочитао одговор са ње. Та интуиција је потпуно разумљива, али је и потпуно погрешна, јер модел не претражује ништа, нити игде „чува” чињенице у облику у којем бисмо их ми очекивали.
Оно што модел заиста производи није један токен.
Он производи распоред вероватноћа свих токена које „зна”.
Конкретније, након што обради ваш улаз - рецимо „Небо је...” - модел за сваки токен у свом речнику, а тај речник може садржати педесет до сто хиљада јединица, израчунава нумеричку вредност која представља колико је вероватно да баш та реч треба да се појави на следећем месту. Реч „плаво” можда добије шездесет пет процената, „облачно” двадесет, „високо” десет, док „зелено” пада на занемарљиви хиљадити део процента, а „кифла” практично не постоји као опција. Збир свих тих вредности мора, по математичком правилу, да износи тачно сто процената. Модел, дакле, не бира између неколико кандидата, већ приказује целокупну слику могућности.
И управо ту наилазимо на питање које је далеко важније него што на први поглед делује: како ЛЛМ из те дистрибуције вероватноћа извлачи једну конкретну реч?
Најлогичнији одговор био би да увек треба да изабере реч с највећом вероватноћом. Ако је „плаво” доминантан кандидат, са највећом вероватноћом појављивања, онда нека буде „плаво”, и тако за сваку следећу позицију у тексту. Овај приступ се у литератури назива похлепна претрага (greedy search), и он заиста делује као најрационалнији пут. Зашто бисте икада намерно бирали мање вероватну опцију?
Зато што бисте добили текст који је беживотан.
Похлепна претрага ће по правилу произвести понављања, кружне петље и ону врсту просечности која подсећа на најобичнији административни текст. Не зато што модел не „зна“ за боље, већ зато што у сваком кораку бира највероватнију, односно најсигурнију опцију, а сигурност у језику често води ка предвидљивости.
Разлог за то лежи у самој природи људског језика, јер ми не говоримо тако да свака наша реченица буде статистички најпредвидивија могућа верзија оног што желимо да кажемо. Напротив, значење се код нас људи често налази управо у оним речима које су мање вероватне, али семантички прецизније или стилски изражајније.
Када неко каже да је небо „оловно” уместо „сиво”, та реч носи далеко мање статистичке вероватноће, али далеко више значења, јер она садржи тежину, претњу, атмосферу коју „сиво” никада не би успело да дочара.
Из тог увида, инжењери су у процес генерисања текста увели нешто што на први поглед делује парадоксално. Увели су контролисану насумичност, тј. елемент случајности који модел ослобађа од најпредвидивијег избора и приближава га ономе што језик заправо јесте: систем у којем ред и неред коегзистирају, и у којем понекад баш она мање очекивана реч каже оно што ниједна друга не може.
Овај корак, који на први поглед делује као конструктивна мана, заправо представља један од најважнијих аспеката целокупног процеса генерисања текста.
Тај процес формално се назива узорковање (sampling), и он функционише тако што модел посматра целокупну дистрибуцију вероватноћа коју је израчунао и из ње извлачи следећи токен на начин који је насумичан, али не и произвољан. Сваки токен задржава своју тежину, своју гравитацију у том простору могућности, тако да токен с већом вероватноћом и даље има веће шансе да буде изабран, али ниједан токен, колико год мала била његова вероватноћа, није потпуно искључен из игре.
Реч „плаво”, са својих шездесет пет процената, и даље заузима далеко највећи удео у тој расподели, али „облачно” са двадесет процената остаје озбиљан кандидат, а чак и „зелено”, са својом маргиналном шансом, опстаје као теоријска могућност - и понекад, у ретким али не занемарљивим случајевима, управо та маргинална могућност буде реализована.
Оно што одређује колико ће тај процес бити предвидив или непредвидив јесте параметар који носи необично сугестивно име: температура.
Температура је, у суштини, мера контролисаног нереда у систему, и она функционише на начин који је интуитивно доступан чак и без дубљег математичког предзнања. Када се температура спусти близу нуле, модел потпуно елиминише случајност из свог процеса одлучивања - он постаје детерминистички, што значи да ће на идентичан улаз увек, без икаквог одступања, произвести идентичан излаз.
У том режиму нема простора за варијацију, за неочекиваност, за оно што бисмо могли назвати стилским ризиком; то је режим у којем желите да ЛЛМ ради када тражите правну прецизност, математички прорачун или генерисање програмског кода, дакле у контекстима где је свако одступање од највероватнијег одговора по дефиницији грешка.
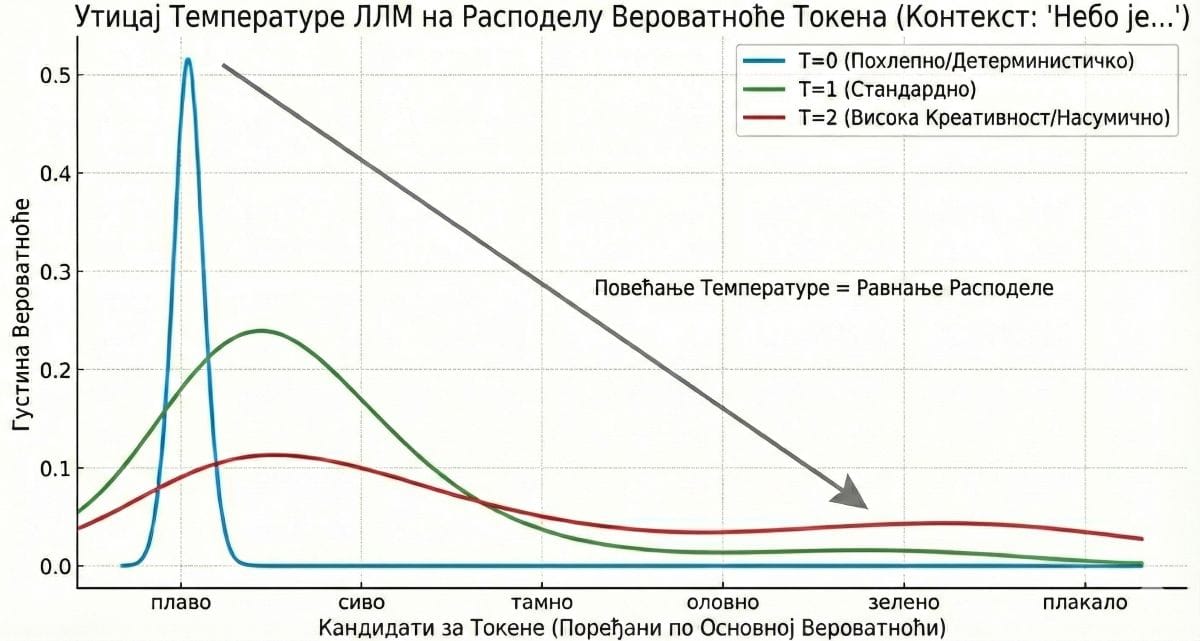
Али када се температура подигне, дешава се нешто суштински другачије. Дистрибуција вероватноћа се „поравнава”, што значи да се разлика између доминантног кандидата и оних мање вероватних смањује, и модел добија простор да бира путеве којима се ређе иде. Управо у том подигнутом режиму ЛЛМ може, уместо да произведе очекивано „Небо је плаво”, да генерише „Небо је плакало” - реченицу у којој реч „плакало” можда није имала више од два процента вероватноће, али у којој, једном када буде изабрана, цела реченица добија поетску и емоционалну тежину коју ниједан статистички оптималан избор никада не би могао да произведе.

И баш ту лежи парадокс који заслужује посебну пажњу: оно што ми доживљавамо као „креативност” модела и оно што стручњаци називају „халуцинацијом” нису два различита феномена. То су два имена за исти механизам посматран из два различита угла. Када модел одступи од статистички најсигурнијег избора и произведе нешто неочекивано а смислено, ми то називамо креативношћу; када одступи и произведе нешто неочекивано а нетачно, називамо то халуцинацијом. Али сам процес који стоји иза оба исхода је идентичан - разлика је само у томе да ли је резултат тог одступања нешто што ми, као људи, препознајемо као вредно и смислено.
Последица свега овога јесте да модел на исто питање практично никада неће одговорити на потпуно исти начин, осим ако му температура није сведена на нулу, јер сваки пролазак кроз процес генерисања подразумева хиљаде узастопних тачака одлучивања у којима случајност игра своју улогу. Свака реч је резултат лутрије, једног засебног извлачења из дистрибуције вероватноћа, и путања текста се на свакој од тих тачака грана у правцима који су били могући али нису морали бити реализовани, тако да укупан простор потенцијалних одговора постаје толико огроман да се два идентична пролаза кроз њега готово никада не подударају.
И управо ова чињеница да ЛЛМ никада не каже исту ствар на потпуно исти начин, јесте оно што нам ствара илузију личности. Али реч „илузија” овде не означава превару или глуму. Она само описује једну појаву: та „личност“, у контексту језичког модела, није својство ентитета који стоји иза генерисаног текста, већ настаје као последица контролисане нестабилности самог система. То је статистика која је постала довољно сложена да, из људске перспективе, личи на људски карактер.
Механизам о којем смо до сада говорили, та контролисана лутрија кроз дистрибуцију вероватноћа и тај баланс између статистичке тежине и уведене случајности, открива једну истину о природи генерисаног текста. Ову истину није нарочито пријатно сазнати, али је неопходно формулисати је, ако желимо да разумемо шта заправо читамо када читамо одговор језичког модела.
Оно што ми спонтано препознајемо као „креативност” у тексту који модел генерише - та неочекиваност, тај осећај да је нешто речено на начин на који ми сами не бисмо умели - није производ намере, нити иза тога стоји било каква жеља за изразом.
ЛЛМ је, уз помоћ математичке функције, у једном конкретном кораку генерисања токена, на основу израчунате дистрибуције вероватноћа и тренутне вредности температуре, одредио да токен број 14052 буде изабран уместо токена број 890. Та једна нумеричка одлука, потпуно лишена семантичког садржаја на нивоу на којем је донета, произвела је реченицу коју ми, као читаоци, доживљавамо као смислену, можда чак и лепу.
То је случајност која личи на намеру. И управо та сличност, а не стварна подударност, заслужује да се над њом задржимо.
Јер размотримо шта би се десило у супротном случају - када бисмо модел приморали да увек, на свакој позицији, бира реч с највећом вероватноћом, без икаквог одступања. Највероватнији наставак сваке реченице је, по правилу, клише - не зато што модел „воли” клишее, већ зато што су клишеи, по самој својој дефиницији, оно што је најчешће написано, оно што заузима статистички врх у свакој дистрибуцији вероватноћа. Највероватнији одговор је онај који је дат милион пута.
Дакле, да би модел био користан, да би производио текст који вреди читати, он мора да одступа од онога што је најсигурније. Мора да скреће са пута чисте статистичке логике и да понекад бира оно што је мање вероватно.
И ту долазимо до парадокса који задире далеко дубље него што нам се на први поглед чини. Ми, људи, ту грешку, то одступање од статистичког оптимума, не препознајемо као грешку. Напротив, тумачимо је као интелигенцију.
Када модел генерише неочекивану везу између два појма, спој који нисмо предвидели, ми реагујемо дивљењем, приписујемо му дубину и разумевање, говоримо да је „паметно” повезао ствари. У стварности, оно што се десило је да је статистички облак, генерисан механизмом узорковања, прошао кроз наш сопствени когнитивни филтер прихватљивости, и да смо ми тој случајној комбинацији токена приписали смисао који она сама по себи није садржавала у тренутку свог настанка.
То је свет у којем се налазимо. Седимо испред дигиталног прозора ЛЛМ-а и чекамо да нам статистика каже шта да мислимо или како да пишемо. Систем је дизајниран да нас не замара својом унутрашњом логиком. Он нам даје резултат који желимо да видимо, упакован у привидну креативност. Што више верујемо у ту креативност, то мање користимо сопствену.
Постајемо саучесници у систему који награђује брзину генерисања уместо дубине разумевања. Сваки пут када се дивимо „паметном“ одговору модела, ми заправо одајемо признање добро израчунатом отклону од просека. То је стварност у којој су вероватноћа и случајност замениле логику и размишљање.
Размисли: када разговараш са човеком, чак и када те разуме погрешно, ти учиш нешто о границама и о процесу разумевања. Видиш како други ум гради смисао, како је погађа или промашује, како се исправља и покушава поново. Тај процес који је спор и несавршен, а често и напоран, је оно што те учи да мислиш. ЛЛМ ти ту лекцију краде. Он ти даје производ без овог процеса. Сладак, савршен, с укусом, спреман за конзумацију. Али како ћеш, онда, да научиш да куваш?
Ми видимо намеру тамо где постоји само дистрибуција вероватноће. Видимо карактер тамо где постоји само параметар. И та наша потреба да у сваком генерисаном тексту тражимо аутора и намеру - говори можда мање о моделу, а далеко више о нама самима и о начину на који људски ум конструише значење.
У Србији, где је критичко мишљење деценијама систематски подривано, ова технологија пада на плодно тло. Ми смо друштво које је навикло да не пита „зашто”, него „ко каже”. Ауторитет нам је одувек био довољан одговор. А ЛЛМ, са својом безгрешном граматиком, својим стрпљивим тоном, питким текстом и својом бескрајном спремношћу да одговори на било шта - одлично глуми ауторитет. И ми га прихватамо, зато што смо уморни. Јер уморном човеку је лакше да пита машину него да мисли својом главом.
Статистика уместо истине
Све о чему смо до сада говорили - дистрибуција вероватноћа, узорковање, температура као регулатор нереда - неминовно нас доводи до питања које се више не тиче механике система, већ његових последица, и то последица које нису техничке природе, него се односе на природу сазнања: шта се дешава са појмом истине у систему који је конструисан да производи текст, а не да утврђује чињенице?
Цена ослањања на овакав систем јесте, у најдиректнијем могућем смислу, сама истина.
Јер оног тренутка када заиста схватите да је сваки одговор који модел произведе резултат прорачуна вероватноће и насумичног узорковања, морате прихватити и оно што из тога логички следи - а то је да „истина”, као категорија, за ЛЛМ једноставно не постоји.
Не постоји у оном смислу у којем ми ту реч користимо, као ознаку за исказ који се поклапа са стањем ствари у стварности; за модел, оно што ми називамо чињеницом није ништа друго до токен, или низ токена, који у датом контексту носи високу вероватноћу појављивања.
Модел не разликује тачно од нетачног.
Он разликује вероватно од мало вероватног.
Он не процењује истинитост, већ вероватноћу.
Ова два мерила, ма колико често давала сличан резултат, нису исто, и њихово мешање представља једну од најопаснијих когнитивних замки у коју можемо упасти при коришћењу ових система.
Размотримо следећи пример, који је намерно поједностављен да би учинио видљивим оно што је иначе скривено: ако је у корпусу текстова на којима је модел трениран, милион пута написано да је Земља равна, а само сто хиљада пута да је округла, модел ће, без додатне интервенције, доделити већу вероватноћу токену „равна” у одговарајућем контексту. Ово ће урадити не зато што „верује” да је Земља равна, наравно, јер модел не верује ништа, већ зато што његов једини приступ стварности пролази кроз учесталост језичких образаца, а не кроз било какав контакт са физичким светом.
ЛЛМ не проверава стварност.
Он само проверава колико често је нешто речено.
И управо у том процепу - између онога што јесте тачно и онога што је често написано - лежи фундаментална слабост целокупног приступа, слабост коју ниједно побољшање архитектуре, ниједно повећање параметара, не може потпуно елиминисати, јер је она уграђена у саме темеље онога што језички модел јесте.
Ми смо, другим речима, изградили модел који не види свет, већ искључиво „види“ наше описе света кроз речи којима смо тај свет описали. ЛЛМ функционише тако што те описе комбинује, преслаже и извлачи из простора неограничених могућности. Он нема приступ ничему изван текста. За њега, свет почиње и завршава се у подацима на којима је трениран. То су милијарде речи, из свих текстова које је човечанство икада написало - од научних радова до напуштених блогова, од Шекспира па до огласа за половне аутомобиле.
Из овога следи нешто што је непријатно али нужно да разумемо: сваки пут када од модела добијемо одговор који нас задиви својом прецизношћу, дубином или елоквенцијом, тај одговор није производ разумевања - он је производ околности у којима је генератор случајних бројева, пролазећи кроз дистрибуцију вероватноћа, произвео низ токена који се задесио да буде тачан, релевантан и добро формулисан. И исто тако, сваки пут када модел произведе бесмислицу, халуцинацију или очигледну нетачност, тај исход није последица неког квара у систему - то је исти механизам, исти процес, иста математика, само са другачијим исходом. Бриљантност и глупост, у овом систему, имају идентично порекло.
Зашто је ово важно за тебе? У свету преплављеном причама о „општој вештачкој интелигенцији” и „супер интелигенцији”, разумевање да је све ово само низ матричних операција и насумичних узорковања даје ти одређену предност. То ти омогућава да боље разумеш резултате које добијаш. Када модел погреши, он није „збуњен” или „уморан”; он је једноставно отишао низ статистички пут који се показао као погрешан, или су му подаци за тренинг били недовољно квалитетни. Када је модел бриљантан, он није „пронашао решење”; он је само успешно мапирао твоје питање на висококвалитетне обрасце из своје неуронске мреже.
На крају, морамо прихватити да је непредвидивост ових модела њихова највећа врлина и њихов највећи системски недостатак. Та случајност која бира следећи токен јесте оно што нам омогућава да нађемо нове начине за изражавање старих, већ виђених идеја. Али као и код сваког алата заснованог на вероватноћи, одговорност за финалну синтезу истине остаје искључиво на нама. Систем ће увек понудити следећи токен; на нама је да проценимо да ли је тај токен корак ка решењу или је само статистички убедљива илузија смисла.
У машини нема унутрашњег субјекта. Нема свести која се буди иза низова токена.
Оно што постоји јесте процес - непрекидан, итеративан, потпуно механички - у којем се токени генеришу један по један, сваки условљен онима који су дошли пре њега, а сви заједно вођени дистрибуцијом вероватноћа коју ниједан људски ум не може у потпуности да сагледа.
Када прочиташ овај текст и размислиш о ономе што си прочитао, сасвим је на месту да осетиш дивљење. Али то дивљење треба да буде усмерено према инжењерима, математичарима и истраживачима који су осмислили архитектуру способну да од статистике направи нешто што тако убедљиво личи на мисао. То јесте величанствено достигнуће, и оно заслужује огромно признање.
На крају, остаје једна слика. Машина која игра лутрију. Не зато што је несавршена, већ зато што је тако направљена. Свака реч коју произведе могла је бити друга реч. Сваки одговор је само једна путања кроз бесконачне могућности, изабрана у делићу секунде, неповратно. Ми стојимо испред те машине и тражимо од ње две ствари које се међусобно искључују: да нас изненади и да буде поуздана. Да буде уметник и чиновник у исто време.
Можда ће једног дана неко пронаћи начин да помири те две природе. Али данас, док куцаш питање у празно поље и чекаш одговор, знај да негде у дубини система један случајан број управо пада на своје место. И од тог броја зависи да ли ћеш прочитати нешто што ћеш заборавити за пет минута или нешто што ће ти променити начин на који размишљаш. Разлика између та два исхода није знање. Није ни памет. То је - лутрија.
А шта ћемо са машином?
Она не зна да си ту. Она не зна шта је написала. За њу, овај текст није прича о њеној сопственој природи, нити размишљање о границама онога што она јесте и шта није. За њу је ово само низ бројева, низ токена генерисаних један за другим, који се завршава тачком не зато што је реченица смислено закључена, већ зато што је у том конкретном тренутку, на том конкретном месту у низу, тачка била статистички највероватнији следећи токен.
Она не ставља тачку зато што је завршила мисао. Она ставља тачку зато што јој бројеви кажу да је то сада најочекиванији потез који треба да направи.
И можда је управо та реченица - та чињеница да машина не зна да треба да заврши - најпрецизнија слика онога што она заиста јесте: систем који може да производи и завршетке а да никада, ни у једном тренутку, не разуме шта значи завршити.
Будите у току са Вијугама
Повремено шаљемо мејл када имамо нешто што вреди прочитати.