Контекстуални прозор (Context Window)

Кад почнемо да користимо велике језичке моделе (ЛЛМ), углавном се не питамо шта модел зна. Питамо се како да му боље поставимо питање, како да добијемо бољи одговор, како да „извучемо максимум”. А у позадини стоји нешто много конкретније, нешто што обликује сваки одговор који добијемо, а о чему ретко када размишљамо док не дођемо до зида. То је контекстуални прозор.
Контекстуални прозор је, најпростије речено, количина текста коју модел може да „држи у глави” док разговара с вама. Све што сте му написали, све што вам је одговорио, сва будућа питања и одговори на њих, сва документа која сте приложили – то све мора да стане у тај прозор. Када се капацитет прозора потпуно испуни, он почиње да се понаша као покретна трака. Најстарије поруке са почетка разговора једноставно „испадају” из њега и неповратно се бришу како би направиле место за ваша најновија питања и одговоре модела. Оно што не може да стане, то не постоји. Модел то не памти и не враћа се на то касније.
И ту се јавља занимљив проблем. Наша логика каже: ако разговарам са неким паметним, он ме слуша, разуме, памти, и у сваком тренутку зна шта смо причали. Кад се обратим колеги у канцеларији, не морам да понављам цео разговор који смо водили пре пар дана. Људски мозак има меморију која траје, филтрира, повезује и извлачи податке када је потребно. Језички модел то нема. Он има прозор – и тај прозор има своје димензије.
Разлог за то је што су велики језички модели, у својој технолошкој основи, системи без стања (stateless). Они немају континуитет сећања нити унутрашњу меморију у коју снештају ваше претходне поруке. Када ЛЛМ-у поставите пето питање у низу, он заправо не „зна” шта сте питали у прва четири, а још мање „зна“ како је одговорио. Па како се онда модел надовезује на претходно написано, и како разговор тече тако глатко?
Ако се сећате, када смо причали о ChatGPT-ју, рекли смо да је то интерфејс односно „посредник“ којег користимо у разговору са моделом. Он сваки пут када поставите ново питање, заједно са тим питањем, изнова пошаље и целокупан дотадашњи историјат разговора. Дакле, сваки нови корак у комуникацији је, заправо, поновно слање целог транскрипта разговора испочетка, тј. од тренутка када сте кликнули на „New Chat“ и започели разговор. Сам модел постоји само у том једном тренутку и има само тај један прозор.
Величина контекстуалног прозора мери се у токенима. Токен није реч у класичном смислу – то је део речи или некад цела реч, некад слог, некад суфикс, некад знак интерпункције. Следећи дијаграм илуструје како се текст „сецка“ на токене и пролази кроз ограничени контекстуални прозор модела.
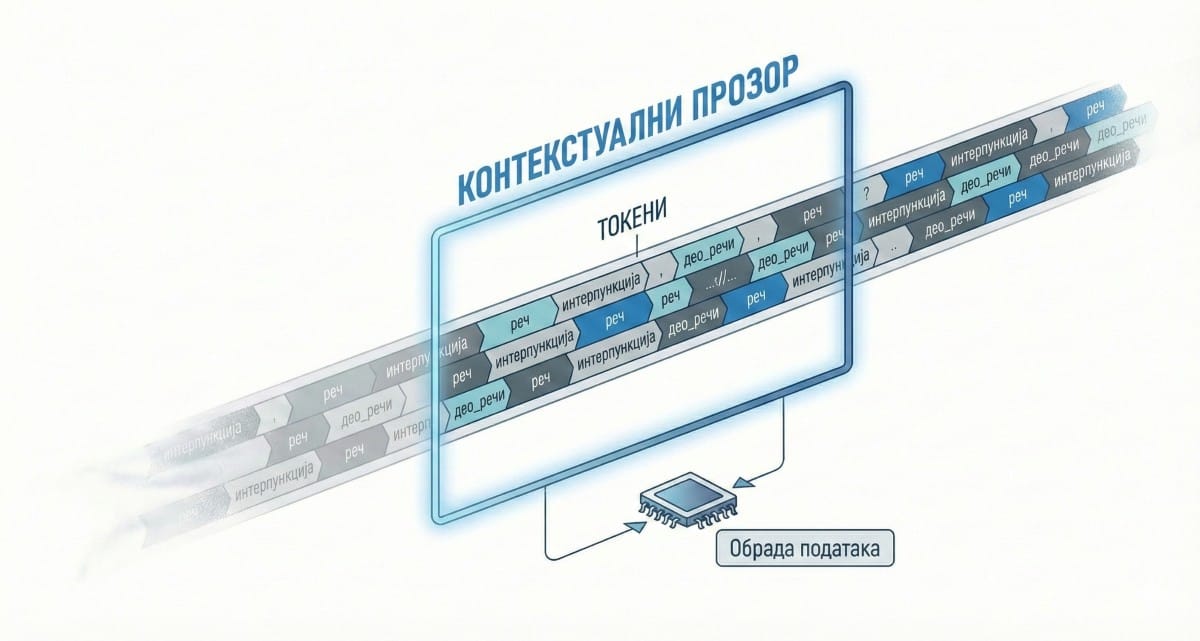
Српски језик, рецимо, потроши више токена по реченици него енглески, што значи да ће, ако радите на српском, ваш контекстуални прозор бити ефективно мањи. Не зато што вам је модел нешто ускратио, већ зато што је наш језик другачије скројен од оног на којем је систем учио.
Већи обим, мања пажња
Данас постоје модели са прозорима од сто хиљада, двеста хиљада, чак и милион токена. Када кажемо да модел има контекстуални прозор од 128.000 токена, то значи да у једном разговору може да „види” око 80.000 речи. То је отприлике дужина једног кратког романа од 150 страна у Б5 формату. На први поглед, звучи импресивно, јер изгледа као да можете да убаците целу књигу и разговарате о њој. И можете. Донекле.
Али постоји разлика између тога да нешто стане у прозор и да модел са тим нечим заиста ради, јер величина прозора није исто што и пажња са којом модел „гледа” његов садржај. Истраживања показују да модели у средишњем делу дугачког контекста почињу да губе прецизност и свој фокус. Почетак добро памте, крај памте још боље, али имају проблема да упамте средину. Овај феномен, познат као „изгубљено у средини“ (lost in the middle), јасно је приказан на следећем графикону.
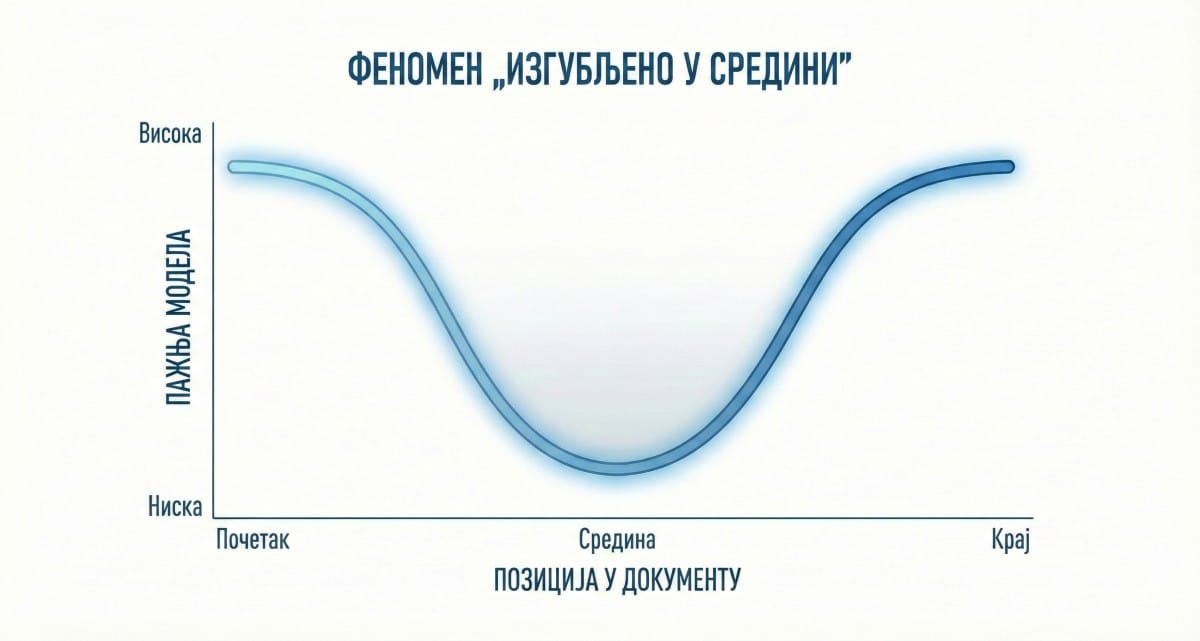
Замислите да сте моделу дали уговор од 80 страница и питали га да пронађе клаузулу о условима за раскид уговора. Ако је та клаузула на 45. страници, постоји реална шанса да модел „прескочи” ту информацију или је непрецизно интерпретира, зато што је статистички механизам пажње пристрастан ка крајевима секвенце. Ово није грешка у имплементацији – ово је структурално ограничење тренутне архитектуре ЛЛМ-ова.
Економија токена и пословна реалност
Када се овај проблем сагледа кроз економску призму, постаје јасно зашто је одлука о томе шта убацити у контекстни прозор заправо стратегијска, а не техничка. Сваки токен који убаците, а који није релевантан за задатак, представља вишак који деградира квалитет одговора и повећава трошкове. Ово је класичан компромис између обима и прецизности, и он је познат сваком инжењеру и сваком менаџеру који је икада радио са ограниченим ресурсима.
Али постоји и цена избора: рачунска сложеност овог механизма расте квадратно са бројем токена. Ако удвостручите величину контекстуалног прозора, четвороструко ћете увећати количину рачунања. То није линеарна скала. То је експоненцијални раст трошкова.
У пракси, ово значи следеће. Када пошаљете моделу документ од 100 страница (око 50.000 речи или 80.000 токена) заједно са питањем, ви плаћате обраду свих тих токена, без обзира на то да ли је за одговор на ваше питање била потребна прва страница или деведесета. Што је још занимљивије, ако поставите следеће питање, у оквиру истог „разговора“ са моделом, апликација коју користите, у позадини поново шаље тих 100 страница, шаље ваше прво питање, шаље одговор на прво питање и тек на крају шаље ваше друго питање моделу. Ово значи да сте за два питања већ потрошили 160.000 токена плус токене за два питања и токене за два дата одговора!
У следећој табели приказане су цене улаза за милион токена за најновије моделе:
|
Провајдер |
Најновији модел |
Цена по 1M input
токена (USD) |
Формула за 160k |
Цена за 160.000 input токена (USD) |
|
OpenAI |
GPT‑5 |
2.50 |
2.50 × 0.16 |
0.40 |
|
Gemini |
Gemini 3 Pro |
2.00 |
2.00 × 0.16 |
0.32 |
|
Claude |
Claude Sonnet 4.5 |
3.00 |
3.00 × 0.16 |
0.48 |
Када погледате ове цене, можда ћете рећи „па и није тако скупо“. Није, ако модел користите за своје личне потребе. Али замислите 50 запослених који сваког дана, у току радног времена, постављају не 2 него 20 питања моделу и шаљу 50, 100 или 150 страница по питању. Сваки токен кошта. Код комерцијалних АПИ-ја, цена се обрачунава по токену – и за улаз и за излаз. Организација која рутински „убацује” целе документе у контекстуални прозор генерише непотребне трошкове који се месечно мере у хиљадама евра, а често и више.
Зато велики контекстуални прозор није исто што и добар контекстуални прозор. Ово је кључна ствар коју многи превиде, нарочито они који мисле да је решење за сваки проблем убацивање још података. Више информација не значи бољи одговор. Ту је и питање латенције, односно времена које прође од вашег питања до одговора који вам даје ЛЛМ. Већи контекст значи спорији одговор.
Ово објашњава зашто је понекад боље започети нови чет (New Chat) него наставити стари. Када започнете нови чет, ви заправо кажете ChatGPT-ју да не мора више да шаље сва претходна питања и одговоре ЛЛМ-у, и почињете са празним контекстуалним прозором. То машини даје фокус. Ако наставите да мрцварите и водите исти разговор данима, мењајући теме, контекстуални прозор се пуни небитним информацијама из прошлости које само сметају у давању одговора на нова питања и на решавању тренутног проблема.
Разумевање граница као предуслов примене
Ко ово треба да зна? Свако ко модел жели да користи за нешто озбиљније од једноставних питања. Ово разумевање је сама срж контекст инжењеринга и представља основни алат за оне људе у организацији чији је посао да стратешки управљају подацима који се шаљу моделу. Ако припремате документацију за тендер и тражите од модела да вам помогне да је уобличите, ви морате да знате колико текста можете да му дате а да одговор и даље буде смислен. Ако аутоматизујете корисничку подршку, морате да разумете да чет-бот после педесет размена питања и одговора почиње да „заборавља” шта је корисник рекао на почетку. Контекстуални прозор није ограничење које ће једног дана нестати, јер је он основна градивна јединица система.
И овде долазимо до нечег што је, бар по мом искуству, важније од самих бројева. Питање није колики је контекстуални прозор. Питање је ко у вашем тиму разуме шта то значи за конкретну употребу ЛЛМ-а који покушавате да уведете у ваше радне процесе. Јер у пракси, одлуке о коришћењу АИ алата доноси неко ко је видео презентацију о њима, одушевио се, и сад, брже-боље жели да се то „уведе”. А онда, три месеца касније, испостави се да систем губи нит разговора после двадесет порука, да корисници добијају контрадикторне одговоре, и да нико не зна зашто. А зашто? Јер нико није размишљао о контекстуалном прозору.
Питање које треба да поставите је: „За који конкретни пословни процес ми треба милион токена, и колико ме то кошта по упиту у поређењу са циљаним приступом од десет хиљада токена?” Одговор на ово питање готово увек показује да је прецизност јефтинија и ефикаснија од обима.
Не кажем да не треба користити моделе са великим контекстуалним прозором. Кажем да треба знати шта је тај прозор и како ради. Не постоји гаранција да ће одговор бити тачан само зато што сте му дали пуно материјала у оквиру инжењеринга контекста. То је радна површина, ограничена и привремена, на којој модел покушава да склопи најбољи могући одговор из онога што му је тренутно доступно, и што у том тренутку „види“.
А ако вас неко убеђује да је милион токена решење за све, запитајте се да ли је тај неко икад покушао да у том милиону токена пронађе грешку кад модел погреши. Количина прочитаних података није исто што и разумевање. То важи за контекстуалне прозоре исто колико и за људе.
Остаје, на крају, оно суштинско питање: ко у вашем окружењу заиста разуме где модел престаје да прати контекст, и то на вашим подацима, у вашем процесу, за ваше радне задатке, са вашим корисницима? Да ли бисте умели да препознате тренутак у којем је одговор који сте добили, у ствари, одговор на нешто друго, а не на ваше питање, зато што је прозор одавно „преклопио“ податке који се односе на оно што сте заправо питали? И ако не бисте могли ви, ко би могао?
Контекстуални прозор је инфраструктурни параметар, а не мера интелигенције и не гаранција квалитета одговора модела. Као и свако ограничење, он само дефинише простор могућности – али квалитет података и резултата унутар тог простора одређује начин на који га користите, а не његова максимална величина. Модели су алати са јасним техничким ограничењима, и разумевање тих ограничења је предуслов за њихову озбиљну примену.
Обећања модела и цена свезнања
Чини се да нема више повратка на мале прозоре, на оне оквире у којима је на почетку стајало тек понеко питање, неколико реченица и понеки документ, јер технологија неумољиво наставља да се развија. Ускоро ће, можда, контекстуални прозор постати довољно широк да у њега стане сваки разговор који смо икада водили, сваки откуцај срца који је забележен неким сензором, свака куповина која је оставила траг у некој бази података, свако јело које нас је изненадило или одушевило и сваки тренутак у којем смо се искрено радовали. Све то би могло бити сложено и повезано тако да може бити унето у модел као једна непрекидна прича о нашем постојању. У неком тренутку у будућности, вештачка интелигенција ће вероватно моћи да „прочита” цео наш живот у једној секунди.
То ће бити наш „лични асистент” и нудиће се као врхунац персонализације, као обећање да ће нас АИ систем разумети боље него што разумемо сами себе, да ће знати шта желимо пре него што то пожелимо и шта нам треба пре него што осетимо потребу. Можда ће то значити и крај приватности какву познајемо, иако се чини да нам је то у овом тренутку мање важно. Ипак, када наш екстерни контекст, учитан у контекстуални прозор ЛЛМ-а, постане бољи од нашег унутрашњег сећања, постоји реална опасност да ћемо се, готово неприметно, претворити у зависника. Питање је да ли ћемо тада уопште моћи да водимо разговор без сугестија „личног асистента“, или да се сетимо рођендана, имена, обећања и света који је постојао пре генеративне вештачке интелигенције.
Будите у току са Вијугама
Повремено шаљемо мејл када имамо нешто што вреди прочитати.